





I. Introduction▲
Qu'est-ce que la NatTable ? Il s'agit d'un composant graphique basé sur SWT
destiné à afficher de manière performante des grandes quantités de
données, dans un format de type tableau. Par dessus ce mécanisme de base sont
disponibles, à moindre coût, une quantité d'autres fonctionnalités :
filtres et tris, groupement de colonnes et de lignes, gestion du presse-papiers, persistance de
l'affichage, mise à jour des données en temps réel et composants
personnalisés de visualisation et modification des données affichées… Les
données sont chargées au fur et à mesure de leur affichage et non pas d'un bloc,
un peu comme le ferait une table SWT avec le « LazyContentProvider » (voir
iciLazyTableViewer).
En bref, le but est de proposer des fonctionnalités proches des tableurs tels qu'Excel ou OpenOffice dans un
composant graphique SWT. La NatTable peut ainsi afficher des jeux de données contenant jusqu'à
un million de lignes et de colonnes. Ce composant, qui fait partie du projet Nebula d'Eclipse a
été initialement créé par Andy TSOI qui lui a donné le prénom de son
épouse Natalie. Dans cet article, nous nous concentrerons sur quelques fonctionnalités de la
NatTable et sur quelques exemples. Il serait en effet bien trop long d'en faire le tour complet.
Pour suivre cet article, il est nécessaire d'avoir des connaissances en SWT et de bien maîtriser les
concepts qui gravitent autour des composants JFace tels que les TableViewer ou les TreeViewer.
II. Charger les données▲
II-A. Source de données▲
La première étape pour explorer les possibilités de la NatTable est d'avoir un jeu de données à afficher. Pour cela nous avons besoin d'un jeu de données assez grand, puisque le propre de la NatTable est d'afficher des grandes quantités de données. Pour cela, nous pouvons utiliser la base statistiques de l'aéroport de San Francisco sur les atterrissages dans cet aéroport depuis juillet 2005. Ces données sont disponibles librement ici : http://www.flysfo.com/media/facts-statistics/air-traffic-statisticsStatistiques Aéroport San Francisco. En ce qui nous concerne, nous travaillons sur le « Aircraft Landing Dataset », que nous modifions pour augmenter le nombre de colonnes :
- colonne « Year » déduite des quatre premiers chiffres de la colonne « Period » ;
- colonne « Month » déduite des deux derniers chiffres de la colonne « Period » ;
- colonne « Average Landing Weight (lb) » déduite de la colonne « Total Landed Weight (lbs) » divisée par le nombre d'atterrissages « Landing count » ;
- ces deux dernières colonnes avec des Kg au lieu des lb.
Le fichier CSV ainsi modifié sera chargé dans notre application puis affiché dans la NatTable. Pour plus de facilité, le fichier créé avec les colonnes supplémentaires est disponible dans les sources de cet article.
Notez qu'au lieu d'un fichier, nous aurions très bien pu extraire des éléments d'une base de données.
II-B. Modèle de données▲
Pour stocker nos données, nous utilisons une simple classe conteneur appelée SanFranciscoData. Elle contient une liste d'éléments représentant chacun une ligne du fichier CSV, SingleData. SingleData est un bean Java très simple, composé simplement des éléments permettant de stocker la valeur de chaque colonne et les accesseurs associés, directement générés via Eclipse. Il est aussi nécessaire, pour certains exemples, qu'elle implémente Comparable. Le code de cette classe est donné ci-dessous :
Le code de la classe SanFranciscoData est donné dans le paragraphe ci-après, car elle contient les méthodes de chargement des données.
II-C. Chargement des données▲
Pour charger les données à partir du fichier, nous utilisons la bibliothèque SuperCSVSuperCSV. L'utilisation de cette bibliothèque n'étant pas le sujet de cet article, il est laissé au lecteur le soin de se documenter si besoin sur son utilisation. Les données sont chargées à partir du fichier d'entrée au sein de la classe SanFranciscoData dont le code est donné ci-dessous :
II-D. Architecture des exemples▲
Pour simplifier la mise en place des exemples, nous créerons une vue dans un plugin Eclipse pour chaque exemple que nous créerons. Le chargement des données se fera au démarrage du plugin, dans la méthode « start » de l'Activator :
Le principe du chargement des données à l'activation du plugin est une méthode efficace pour un prototypage rapide mais est à proscrire absolument dans un cas standard !
Les dépendances de votre plugin doivent être les suivantes :
- org.eclipse.runtime ;
- org.eclipse.ui ;
- org.eclipse.ui.forms ;
- org.eclipse.widgets.nattable.core ;
- org.eclipse.widgets.nattable.extension.glazedlists ;
- ca.odell.glazedlists.
Les dépendances aux GlazedLists sont optionnelles, mais vont être utilisées dans certains exemples comme le tri des colonnes.
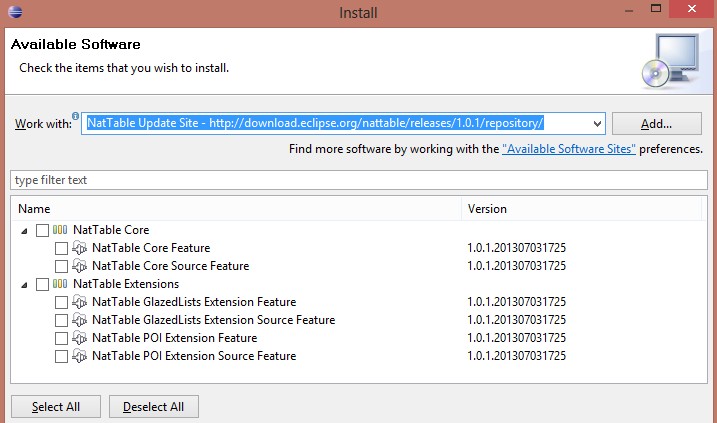
Les plugins de la NatTable peuvent être installés dans votre distribution
Eclipse via les repositorys de la NatTable, dont la dernière livraison est
disponible à cette adresse :
http://download.eclipse.org/nattable/releases/1.0.1/repository/
Sélectionnez les éléments « NatTable Core », « NatTable POI
Extensions » et « NatTable GlazedLists Extension ».
Enfin, pour faciliter la mise en place de nos vues, nous créons une super classe qui sera commune à toutes nos vues, « NatTableView.java ». Elle permet un accès simplifié à notre modèle et met en place les éléments communs à toutes nos vues.
Tout est maintenant en place pour aborder le vif du sujet !
III. Un premier exemple simple▲
III-A. Le fonctionnement de la NatTable▲
La NatTable ne repose pas sur des composants SWT classiques de type Composite, pas
plus que sur un composant Table standard. Celui permet de manipuler de grandes
quantités de données « virtuelles » sans perte de
performance : les éléments graphiques sont calculés et
créés seulement lors de l'affichage à l'utilisateur.
Les différentes fonctionnalités disponibles sont ajoutées à la NatTable via des
éléments appelés « layers ». Chaque layer définit une
fonctionnalité et ils sont ainsi « empilés » les uns sur les autres afin de
créer le rendu final. Par exemple, le diagramme ci-dessous permet de visualiser comment les layers
sont utilisés en couche pour créer une NatTable :

La pile de layer centrale « Body Layer Stack » définit les
fonctionnalités au sein de la table en elle-même, deux autres piles de layers
permettent de définir le comportement des en-têtes de colonne et de ligne,
tandis qu'une dernière pile définit le comportement du coin supérieur,
jonction entre les en-têtes de colonnes et de lignes. Tout en bas de chaque pile de
layers se trouve un élément « DataLayer » qui contient
simplement l'accès aux données de la NatTable.
Chaque pile de layers est agencée au sein de la NatTable dans une région, l'agencement de ces
régions étant lui-même agencé par un layer, dans l'exemple du schéma il s'agit
d'un GridLayer, agencement le plus classique.
Chaque layer pourra ensuite être configuré plus précisément grâce à des registres
de configuration « UIBindingRegistry » et « ConfigRegistry » qui
nous permettront par exemple de mettre en place le style des cellules, l'édition des cellules ou
encore les raccourcis clavier.
Lorsqu'une action utilisateur ou une commande est déclenchée au niveau de la NatTable, elle sera
propagée au sein des différents layers, de celui de plus haut niveau vers le DataLayer,
jusqu'à ce qu'un layer réagisse à la commande. Puis, un événement sera
lancé pour informer tous les layers qu'une actualisation est potentiellement nécessaire. Cet
événement, celui-ci sera propagé au sein de tous les layers, peu importe qu'un layer
réagisse à cet événement ou non. On pourra réagir à cet événement
en implémentant l'interface « ILayerListener ».
III-B. La première NatTable▲
Créons notre première NatTable ! Pour commencer, créons la vue nommée « BasicExample » dans notre plugin. Pour gérer les données, la NatTable a besoin, comme n'importe quel viewer d'un « data provider ». Dans le cas de la NatTable, ces éléments implémentent l'interface « IDataProvider ». Nous pouvons créer dans la classe « NatTableView.java » la méthode « getSanFranciscoDataProvider » qui nous permettra de charger dans toutes nos tables les éléments de notre modèle.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
// ...
/**
* Retourne l'accesseur aux donnees du modele pour la NatTable
* @return
*/
protected IRowDataProvider<SingleData> getSanFranciscoDataProvider() {
return new ListDataProvider<SingleData>(getModel().getData(),
new ReflectiveColumnPropertyAccessor<SingleData>(SanFranciscoData.getBeanHeaders()));
}
// ...
Analysons cette courte méthode pourtant puissante. Premièrement, pour toutes
les données de type liste, la NatTable propose un provider par défaut, le
« ListDataProvider ». Cet élément est un peu le pendant de
l'ArrayContentProvider dans les viewers JFace classiques.
Le premier paramètre du constructeur est simplement la liste des données à afficher. Le
deuxième est la manière dont la NatTable va accéder aux données du modèle,
colonne par colonne.
Ici, nous utilisons l'élément le plus automatique, un ReflectiveColumnPropertyAccessor. Comment
fonctionne cet élément ? Il accède aux attributs de chaque élément du
modèle par réflexion, ce qui impose que les éléments respectent la convention de
nommage des « beans » Java pour les accesseurs. La Map fournie au constructeur de
cette classe permet de donner les en-têtes de colonne pour chaque attribut.
Qu'est-ce qu'un bean Java ? Pour faire court, il s'agit d'un objet où, entre autres conventions, les attributs et leurs accesseurs suivent une convention de nommage : le getter est nommé « get » + le nom de l'attribut avec la première lettre en majuscule (ou « is » dans le cas d'un booléen) ; le setter est nommé « set » + le nom de l'attribut avec la première lettre en majuscule. Par exemple, pour un attribut name on aura « getName » et « setName". Plus d'infos iciJavaBeans sur Wikipedia.
Il faut ensuite créer la NatTable. Dans la classe BasicExample.java, modifiez le code comme suit :
Dans la méthode « createNatTable », les différents
éléments de la NatTable sont configurés un à un. En premier, on
crée les layers pour la partie centrale de la table, l'affichage des données
proprement dit. Cette pile de layers nécessite de connaître le DataProvider de
la NatTable, pour construire le DataLayer qui encapsule les données qui sont
affichées dans la NatTable (rappelez-vous que c'est toujours le layer de plus bas
niveau). Puis nous empilons les layers afin de créer des fonctionnalités
basiques : un SelectionLayer, puis un ViewportLayer. Le ViewportLayer permet de
mettre en place le défilement dans la NatTable. Le SelectionLayer quant à lui
suit la sélection courante dans la NatTable.
On crée ensuite les layers pour les en-têtes de colonnes, puis les en-têtes de lignes. Notez que
dans les deux cas, le layer central sert de référence pour le positionnement des
éléments et est passé au constructeur des layers. De même, le SelectionLayer est
donné en argument pour pouvoir suivre la cellule sélectionnée.
Puis nous construisons le layer du coin supérieur gauche de la NatTable grâce aux éléments
par défaut. Enfin, nous rassemblons ces quatre layers dans le GridLayer qui va agencer ces
éléments. Ce dernier layer nous permet de finaliser la construction de la NatTable. Nous
pouvons lancer notre application pour observer le résultat :
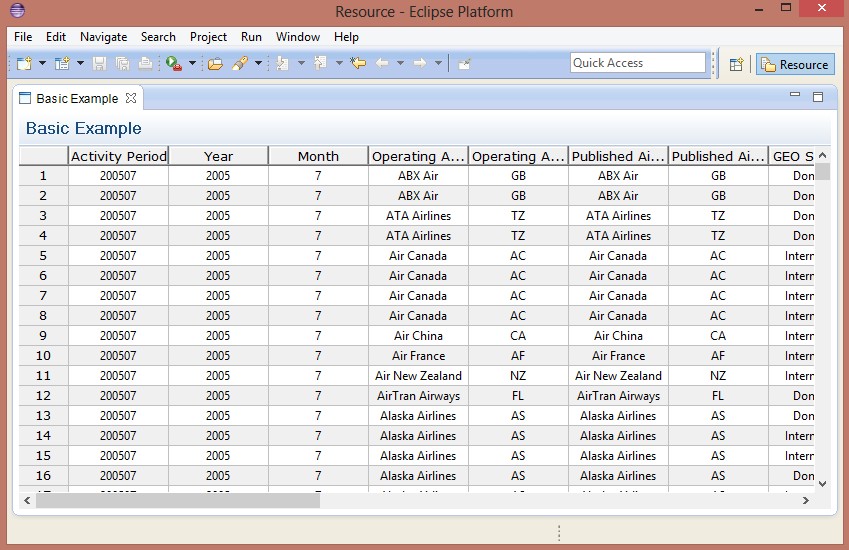
Maintenant que les bases de la NatTable sont posées, nous allons passer en revue quelques fonctionnalités majeures.
IV. La gestion des colonnes▲
IV-A. Figer les lignes et colonnes▲
Lorsqu'on manipule une grande quantité de données, il est vite pratique de pouvoir figer l'affichage de certaines lignes et de certaines colonnes, à la manière de l'option « Figer les volets » d'Excel. Créez une nouvelle vue « ColumnsExample » dans notre plugin et insérez-y le code suivant :
Dans ce code, nous utilisons, pour gagner du temps, un
« DefaultBodyLayerStack ». Cet élément met en place un
certain nombre de layers qui proposent des fonctionnalités
générales : réordonner les colonnes par glisser-déplacer ou les
cacher et la couche de sélection et de défilement (le
« SelectionLayer » et « ViewportLayer » dont nous
avons déjà parlé).
Nous mettons ensuite en place le mécanisme pour figer les colonnes, à travers un élément
« FreezeLayer » et un « CompositeFreezeLayer » qui va gérer
l'agencement des différents layers et l'affichage des éléments une fois que les
lignes/colonnes auront été figées.
Après cela, nous créons les en-têtes de lignes et colonnes, puis le GridLayer global. Enfin, dans le constructeur de
la NatTable, nous mettons l'option d'autoconfiguration à faux afin de créer notre propre
configuration. Nous ajoutons donc à notre NatTable une configuration par défaut et les
raccourcis clavier associés à l'ancrage des lignes et des colonnes. En dernier lieu, il faut
absolument penser à appeler la méthode « natTable.configure() » afin
d'appliquer nos paramètres.
Nous pouvons ensuite observer le résultat en lançant notre application : appuyer sur Ctrl+Maj+F
afin de figer les volets, et sur Ctrl+Maj+U pour les libérer.

Vous pouvez aussi tester le réagencement des colonnes en les faisant glisser comme dans une table SWT classique.
IV-B. Afficher/cacher les colonnes▲
Dans le paragraphe précédent, nous avons mentionné qu'il était possible grâce au « DefaultBodyLayerStack » de cacher et afficher des colonnes. Pourtant, rien ne semble l'indiquer dans notre exemple précédent. Cependant, ajoutez la ligne suivante juste avant l'instruction « natTable.configure() » :
// ...
natTable.addConfiguration(new HeaderMenuConfiguration(natTable));
natTable.configure();
// ....Cet élément permet de créer un menu contextuel par défaut sur les en-têtes de colonnes. Relancez notre exemple et observez le résultat :
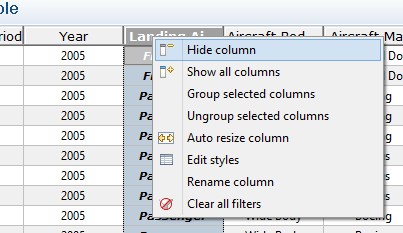
Vous pouvez ainsi cacher des colonnes à votre guise, les renommer, ou encore les redimensionner. Mais l'instruction pour les grouper n'a aucun effet ! Ceci tout simplement parce que nous n'avons pas configuré de layer pour grouper des colonnes. Regardons donc comment faire.
IV-C. Grouper des colonnes▲
Encore une fois, grouper des colonnes passera par la mise en place des layers adaptés. Pour cela, remplacez simplement le « DefaultBodyLayerStack » par un « ColumnGroupBodyLayerStack ». Le constructeur de cet élément prend en paramètre un objet de type « ColumnGroupModel » qui stocke les groupes de colonnes. Puis, nous modifions le layer des en-têtes de colonnes et lui ajoutons un layer « ColumnGroupHeaderLayer ». De fait, notre classe devient la suivante (seules les modifications sont laissées visibles) :
Sans plus attendre, regardons le résultat : après sélection de plusieurs colonnes avec la touche Maj, et un clic sur « Group columns » dans le menu contextuel, une fenêtre s'affiche pour nous permettre d'indiquer le nom du groupe et les colonnes sont groupées automatiquement. On peut par ailleurs réduire le groupe en double-cliquant sur son en-tête.

Par ailleurs, nous pouvons indiquer les groupes de colonnes à établir directement lors de la construction de la NatTable, en modifiant l'objet « ColumnGroupHeaderLayer, » par exemple comme suit :
// ...
// Ajout d'une surcouche sur les en-tetes de colonnes pour les groupes
ColumnGroupHeaderLayer columnGroupHeaderLayer = new ColumnGroupHeaderLayer(columnHeaderLayer,
bodyLayer.getSelectionLayer(), columnGroupModel);
columnGroupHeaderLayer.addColumnsIndexesToGroup("Date", 0,1,2);
columnGroupHeaderLayer.addColumnsIndexesToGroup("UnBreakable Airlines", 3,4,5,6);
columnGroupHeaderLayer.setGroupUnbreakable(3);
// ...Dès l'affichage de la NatTable, les groupes sont déjà construits et les quatre colonnes se reportant aux compagnies ne peuvent pas être dégroupées.
IV-D. Gérer les colonnes affichées▲
Une possibilité intéressante est aussi de proposer à l'utilisateur de choisir lui-même les colonnes à afficher dans la NatTable. Pour cela, nous allons ajouter à notre menu contextuel sur les colonnes une action pour sélectionner les colonnes à afficher. Modifiez la partie configuration de notre exemple avec le code suivant :
// ...
// Configuration de la NatTable
natTable.addConfiguration(new DefaultNatTableStyleConfiguration());
natTable.addConfiguration(new DefaultFreezeGridBindings());
// Creation du dialogue de choix des colonnes
DisplayColumnChooserCommandHandler columnChooserCommandHandler = new DisplayColumnChooserCommandHandler(
bodyLayer.getSelectionLayer(),
bodyLayer.getColumnHideShowLayer(),
columnHeaderLayer,
columnHeaderDataLayer,
columnGroupHeaderLayer,
columnGroupModel);
compositeFreezeLayer.registerCommandHandler(columnChooserCommandHandler);
natTable.addConfiguration(new HeaderMenuConfiguration(natTable) {
@Override
protected PopupMenuBuilder createColumnHeaderMenu(NatTable natTable) {
return super.createColumnHeaderMenu(natTable).withColumnChooserMenuItem();
}
});
natTable.configure();
// ...Lancez ensuite notre exemple : si vous cliquez sur l'élément « Choose columns », vous pouvez sélectionner les colonnes à afficher.

IV-E. Trier les données dans les colonnes▲
Pour trier les données dans les colonnes, la NatTable utilise les GlazedLists, un
projet qui permet de trier et filtrer des listes très simplement, permettant leur
intégration rapide au sein d'une table par exemple. Pour plus d'informations,
consultez le site officiel du projetProjet GlazedLists.
La première étape est donc de transformer notre liste de données en une SortedList qui sera
utilisée par la NatTable pour manipuler les données. Pour ce faire, nous modifions
l'implémentation par défaut de la méthode
« getSanFranciscoDataProvider() ». Puis, comme pour les autres fonctionnalités,
la mise en place du tri se fait via un nouveau layer positionné sur les en-têtes de colonnes.
Le code ci-dessous donne les modifications à apporter à la classe
« ColumnsExample.java ».
Cette configuration permet d'activer le tri « par défaut » sur les colonnes qui va effectuer le tri des données avec des comparateurs par défaut (ordre lexicographique pour les chaînes de caractères par exemple). On peut observer le résultat directement en lançant l'application et en cliquant sur les en-têtes de colonnes.

Notez le raccourci clavier pour établir le tri sur plusieurs colonnes :
Alt+Maj+clic gauche. Si vous souhaitez modifier les raccourcis clavier, utilisez une
autre implémentation de la classe « DefaultSortConfiguration »
au lieu de la « SingleClickSortConfiguration » que nous avons
utilisée.
Si vous souhaitez mettre en place un comparateur personnalisé, il vous faudra enregistrer celui-ci dans
l'objet ConfigRegistry et l'enregistrer en remplacement du comparateur par défaut. Pour
désactiver le tri sur une colonne, utilisez un NullComparator en lieu et place d'un comparateur
personnalisé. Par exemple, l'extrait ci-dessous montre comment désactiver le tri sur la
première colonne « Period » et effectuer le tri sur
« Airline » en fonction de la taille de son nom au lieu de l'ordre lexicographique.
Dernier point, au cas où vous ne souhaitez pas passer par les GlazedLists, vous pouvez définir votre propre implémentation de « ISortModel » et l'utiliser dans votre layer « SortHeaderLayer » au lieu d'utiliser le « GlazedListsSortModel ». Gardez cependant à l'esprit que l'utilisation des GlazedLists dans votre NatTable vous garantit des performances accrues (sans compter le gain - substantiel - en termes de nombre de lignes de code).
V. Gérer les données▲
V-A. Les données d'entrée▲
La NatTable comme nous l'avons vu repose entièrement sur un layer de plus bas niveau, le DataLayer. Ce layer est toujours construit à l'aide d'un objet qui implémente l'interface « IDataProvider ». Dans les exemples précédents, nous avons toujours utilisé un provider par défaut, le « ListDataProvider ». Ce provider permet de construire très simplement un provider à partir d'une liste d'objets et d'un autre objet de type « ReflectivePropertyColumnAccessor » construit à partir de la liste des attributs des objets contenus dans la liste. Si cette méthode est très adaptée pour des objets de type « beans », elle peut être inadéquate si vos objets ne respectent pas cette convention. Dans ce cas, la solution est de créer un nouveau « data provider » qui implémente directement l'interface « IDataProvider ». Cette interface, très simple, requiert les méthodes suivantes :
- int getColumnCount() : retourne le nombre de colonnes ;
- getRowCount() : retourne le nombre de lignes, i.e. le nombre total d'objets ;
- Object getDataValue(int columnIndex, int rowIndex) : retourne la valeur à la ligne et la colonne indiquée ;
- void setDataValue(int columnIndex, int rowIndex, Object newValue) : modifie la valeur à la ligne et la colonne indiquée.
Si vous souhaitez, par la suite, accéder directement aux lignes depuis votre DataProvider (et donc à vos objets), vous devez implémenter en outre l'interface « IRowDataProvider<T> ». Par ailleurs, si vos objets sont contenus dans une liste, sans être des « beans », vous pouvez utiliser le « ListDataProvider », en redéfinissant votre propre implémentation de « IColumnAccessor », comme le montre en partie cet exemple sur nos objets SingleData :
protected IRowDataProvider<SingleData>
getSanFranciscoDataProvider() {
return new ListDataProvider<SingleData>(getModel().getData(),
new IColumnAccessor<SingleData>() {
@Override
public Object getDataValue(SingleData rowObject,
int columnIndex) {
switch (columnIndex) {
case 0:
return rowObject.getPeriod();
// ...
}
}
@Override
public void setDataValue(SingleData rowObject,
int columnIndex, Object newValue) {
switch (columnIndex) {
case 0:
rowObject.setPeriod(// ...
break;
// ...
}
}
@Override
public int getColumnCount() {
return 20;
}
});
}V-B. Dériver des données▲
V-B-1. Créer une colonne dérivée▲
Il est parfois utile d'afficher dans une colonne des informations
supplémentaires établies à partir d'autres colonnes. La NatTable
permet de créer efficacement ce genre de colonnes en ne modifiant pas le
modèle, permettant ainsi de ne pas surcharger les données chargées
en mémoire. La création de ce genre de colonne passe par la
définition ou le raffinement d'un objet de type
« IColumnPropertyAcessor » qui va simplement créer la
donnée au fur et à mesure de l'affichage.
Créez la vue DataExample.java, qui hérite de notre classe squelette NatTableView.java avec le contenu
suivant :
La première étape est de définir un objet de type
« IColumnPropertyAccessor », construit dans notre exemple
à partir d'une implémentation par défaut
(« ReflectiveColumnPropertyAccessor »). Notez que nous
aurions très bien pu, comme dans le paragraphe précédent utiliser
un simple « IColumnAccessor ». Cet accesseur nous permet de
créer « artificiellement » une colonne en première
position, créée à partir des colonnes du mois et de l'année.
L'introduction de cette colonne passe par la création d'un identifiant pour
cette colonne qui ne correspond évidemment pas à un attribut du
modèle, que nous nommons arbitrairement « humanDate ».
Il faut ensuite créer un data provider particulier pour les en-têtes de colonnes, qui va afficher le
texte idoine en en-tête de notre colonne dérivée. Pour les autres colonnes, on se sert
simplement de la transposition attribut-texte de notre modèle. On peut observer le résultat
dans notre vue nouvellement créée :

V-B-2. Créer une ligne dérivée▲
La NatTable permet de mettre en place, en dernière position, une ligne qui va donner un résumé des lignes précédentes, charge au développeur de choisir ce qu'il veut afficher : la somme des éléments, leur moyenne, le nombre moyen de lettres par mot, etc. Encore une fois, cela passera par un layer, nommé « SummaryRowLayer ». Pour notre exemple, nous allons reprendre le code de l'exemple précédent en reconstruisant un GridLayer personnalisé qui nous permettra d'intégrer la ligne de sommaire. Celle-ci affichera trois informations : le nombre total d'atterrissages, et le poids total moyen en lb et en Kg. Modifiez le code de l'exemple « DataExample » comme suit :
Plusieurs choses sont à noter, outre l'introduction du layer « SummaryRowLayer ». Premièrement, nous créons une configuration dérivée de la « DefaultSummaryRowConfiguration ». Cette configuration crée le style par défaut, ainsi que la valeur par défaut pour les colonnes non impactées, à savoir « … ». Puis nous enregistrons pour chaque colonne souhaitée le type d'opération à produire sur les données. Par exemple pour les atterrissages, nous utilisons un objet « SummationSummaryProvider » par défaut, qui est configuré pour effectuer la somme des éléments sur toutes les lignes. Pour la moyenne nous créons notre propre objet « LandingsAverageProvider ». Notez que l'indication de la colonne impactée se fait via l'instruction « SummaryRowLayer.DEFAULT_SUMMARY_COLUMN_CONFIG_LABEL_PREFIX + 19 », où 19 est l'index de la colonne. Si vous souhaitez appliquer une configuration sur toutes les colonnes, il suffit de supprimer l'index pour ne garder que « SummaryRowLayer.DEFAULT_SUMMARY_COLUMN_CONFIG_LABEL_PREFIX ». On peut visualiser le résultat en dernière position de la NatTable :

V-C. Filtrer les données▲
Autre fonctionnalité classique, le filtre sur les données. Encore une fois,
la NatTable va tirer toute sa puissance des GlazedLists et proposer à l'utilisateur
(ainsi qu'au développeur !) une manière puissante de filtrer les
données. Pour cela, nous allons dans un premier temps utiliser une FilterList du
projet GlazedLists, tout comme précédemment nous avons utilisé une
SortedList. Il faut donc modifier en conséquence notre méthode
getSanFranciscoDataProvider. Puis il faut mettre en place les outils de filtre. Cela se
fait en deux étapes, en mettant en place tout d'abord un layer sur les en-têtes
de colonnes qui va activer le filtrage de type
« FilterRowHeaderComposite ». C'est cet élément qui va
tirer parti des fonctionnalités de la FilterList (notez que vous pouvez aussi passer
par une implémentation « maison » de l'interface
« IFilterStrategy »).
Enfin, il faut configurer la NatTable avec nos fonctions de filtre personnalisées, si besoin. Dans notre
cas, cela va en deux parties. La première configuration permet de forcer l'affichage de l'icône
de filtre même si aucun filtre n'est actif. La deuxième permet de mettre en place une liste
déroulante de choix sur le type de vol (« Domestic » ou
« International ») ce qui permet de faciliter le choix de l'utilisateur.
Le fragment de code ci-dessous montre les éléments à modifier dans notre classe
« DataExample » afin d'activer ces fonctionnalités :
Lorsqu'on lance l'application, on observe bien la mise en place des filtres sur nos colonnes. Dans la capture d'écran, on a filtré les données correspondant aux atterrissages ayant eu lieu au mois de décembre.

V-D. Grouper les données par valeur▲
La NatTable permet aussi de grouper les données par valeur de manière à les représenter sous forme d'arbre dans la NatTable. Ce comportement fait penser à la fonctionnalité de tableau croisé dynamique dans Excel. Elle peut être utile sur les jeux volumineux de données où certaines peuvent être regroupées entre elles. Pour cela, il suffit d'utiliser un layer de données de type « GroupyByDataLayer », couplé à un modèle de données « GroupByModel ». Il faut ensuite configurer le « GridLayer » final en y ajoutant un composite d'affichage des groupements effectués. Enfin, il faut ajouter un menu contextuel sur le composite précédent afin de pouvoir désactiver les groupements. L'extrait suivant montre les modifications à effectuer sur notre classe « DataExample » :
Vous pouvez sans plus attendre visualiser le résultat. Faites glisser les en-têtes des colonnes vers le bandeau juste au-dessus de la NatTable pour activer le groupement. Par un clic droit sur ce même bandeau, vous pouvez désactiver le groupement. Dans l'exemple ci-dessous, nous avons groupé les données successivement par année, par type de vol (domestique ou international), puis par mois.

V-E. Récupérer la sélection▲
La NatTable est un provider de sélection, au sens « JFace » du terme c'est-à-dire qu'elle est capable de renvoyer les éléments sélectionnés sous la forme d'une « ISelection », permettant ainsi d'utiliser les mécanismes classiques et donc de l'enregistrer en tant que provider pour la plateforme Eclipse dans le cas d'une intégration dans une application RCP par exemple. Ainsi si vous intégrez le code ci-dessous à notre exemple, les éléments sélectionnés seront affichés dans la console :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
// ...
natTable.configure();
// Creation des evenements de selection
ISelectionProvider selectionProvider = new RowSelectionProvider<>(selectionLayer, provider, false);
selectionProvider.addSelectionChangedListener(new ISelectionChangedListener() {
@Override
public void selectionChanged(SelectionChangedEvent event) {
IStructuredSelection selection = (IStructuredSelection) event.getSelection();
Iterator<?> it = selection.iterator();
while (it.hasNext()) {
SingleData data = (SingleData)it.next();
System.out.println("Selection of data: " + data.getManufacturer()
+ data.getAircraftModel());
}
}
});
return natTable;
// ...
Le dernier argument du constructeur, booléen, indique - s'il est à vrai - que l'on souhaite uniquement être informé des sélections sur des lignes complètes.
V-F. Grouper des lignes▲
De même que nous avons groupé des colonnes, il est aussi possible de grouper des lignes. Malheureusement, le fonctionnement est moins souple et impose des groupements de lignes fixés à la création de la NatTable. De plus, si une ligne n'est pas ajoutée à un groupe elle n'apparaît pas dans la table. L'exemple ci-dessous crée des groupements de 50 lignes dans notre exemple « DataExample » :
On peut observer le résultat en lançant notre application. Notez que l'on ne voit pas la ligne de « sommaire ». D'autre part, le groupement de lignes est d'un intérêt limité dans notre exemple !

VI. Configurer la NatTable▲
VI-A. Comment fonctionne la configuration▲
Dans la plupart de nos exemples, nous avons contribué à la configuration de
la NatTable par plusieurs méthodes. Pour cela nous avons appelé la méthode
« natTable.addConfiguration(IConfiguration) », puis
réimplémenté la méthode « configureRegistry(IConfigRegistry
configRegistry) ». Au sein de cette méthode, nous avons appelé,
chaque fois que c'était nécessaire, la méthode
« configRegistry.registerConfigAttribute() ».
Pour rappel, voici un petit exemple de ce qui a été fait pour filtrer les atterrissages par type de vol
dans l'exemple « DataExample » :
/**
* Configuration des filtres sur les lignes specifiques a nos donnees.
* @author A. BERNARD
*
*/
public class LandingsFilterConfiguration extends AbstractRegistryConfiguration {
@Override
public void configureRegistry(IConfigRegistry configRegistry) {
// Affichage de l'icone de tri meme si inactif
configRegistry.registerConfigAttribute(CellConfigAttributes.CELL_PAINTER,
new FilterRowPainter(new FilterIconPainter(GUIHelper.getImage("filter"))),
DisplayMode.NORMAL,
GridRegion.FILTER_ROW);
// Filtre par liste deroulante sur le type de vol
configRegistry.registerConfigAttribute(EditConfigAttributes.CELL_EDITOR,
new ComboBoxCellEditor(Arrays.asList("Domestic", "International")),
DisplayMode.NORMAL,
FilterRowDataLayer.FILTER_ROW_COLUMN_LABEL_PREFIX + 7);
// Application du style sur le background de la ligne de filtre
final Style rowStyle = new Style();
rowStyle.setAttributeValue(CellStyleAttributes.BACKGROUND_COLOR, GUIHelper
.getColor(197, 212, 231));
configRegistry.registerConfigAttribute(CellConfigAttributes.CELL_STYLE, rowStyle,
DisplayMode.NORMAL, GridRegion.FILTER_ROW);
}
}Vous vous êtes sans doute demandé quels concepts se cachaient derrière ces configurations, il est temps de les détailler ! Chaque configuration implémente l'interface « IConfiguration », qui permet d'accéder à deux objets centraux de la configuration de la NatTable. Tout d'abord, le « ConfigRegistry » est un objet qui contient les informations de configuration suivantes :
- le style des cellules ;
- l'édition des cellules ;
- les comparateurs pour le tri ;
- et toute autre information arbitraire souhaitée.
Cet objet possède un équivalent pour les bindings clavier et souris liés aux configurations, le « UiBindingRegistry ». Ce registre est accessible, comme le précédent, via une méthode idoine de l'interface « IConfiguration » : « configureUiBindings(UiBindingRegistry) ». Chaque layer de la NatTable (et donc la NatTable elle-même) définit une configuration par défaut qui peut être désactivée par un booléen « autoconfigure » dans le constructeur :
final NatTable natTable = new NatTable(parent, compositeGridLayer, false);Le diagramme UML simplifié ci-dessous montre l'architecture de la configuration de la NatTable :

Dans ce paragraphe, nous verrons comment appliquer des styles aux cellules et comment activer l'édition.
VI-B. Appliquer un style aux cellules▲
Le moyen le plus flexible pour appliquer un style aux cellules est de passer par un « CellLabel ». Il s'agit tout simplement d'une chaîne de caractères qui va être utilisée pour identifier une cellule dans la NatTable. Par exemple, appliquer un style particulier à des cellules qui contiennent des erreurs, ou bien les afficher comme des cases à cocher. Pour chaque style que nous définirons, nous devrons indiquer à quel état de la cellule ce style s'applique. Pour cela, nous utiliserons l'interface « DisplayMode », qui contient trois éléments :
- « Normal » : l'état standard d'une cellule ;
- « Select » : lorsqu'une cellule est sélectionnée ;
- « Edit » : lorsqu'une cellule est en cours d'édition.
Pour attacher un « label » à une cellule, il est nécessaire de l'ajouter au layer concerné, par la méthode « ILayer.setConfigLabelAccumulator(ILabelAccumulator) ». L'API de la NatTable nous propose deux implémentations de l'interface « ILabelAccumulator » qui devraient suffire à la plupart des utilisations :
- CellOverrideLabelAccumulator : applique les labels à des cellules contenant une valeur spécifique ;
- ColumnOverrideLabelAccumulator : applique les labels à toutes les cellules d'une colonne.
Bien évidemment, vous pouvez définir votre propre implémentation de
cette interface.
Sans plus attendre, voyons cela sur un exemple simple : créez une nouvelle vue pour ces exemples
appelée « CellsExample.java » et affectez-lui le code suivant :
Cet exemple affiche le contenu de la colonne « Landing Aircraft Type » sous la forme d'une case à cocher. Pour cela, nous enregistrons tout d'abord un label, « LABEL_AC_TYPE » sur la colonne. Puis nous configurons la NatTable pour prendre en compte cette configuration, qui définit la manière dont la cellule est affichée (une case à cocher) et la manière dont on convertit la donnée de la case à cocher (qui est un booléen) vers la donnée du modèle (dans notre exemple une chaîne de caractères) et vice-versa. On peut visualiser le résultat en démarrant notre exemple :

La méthode « registerConfigAttribute », en plus du label et
de l'objet « DisplayMode » dont nous avons parlé dans le
paragraphe précédent, requiert deux attributs : un de type
« ConfigAttributes<ICellPainter> » et l'autre de type
« ICellPainter ».
Il existe différents ConfigAttributes prédéfinis dont voici la liste et une courte
description :
- « BACKGROUND_COLOR » : pour la couleur de fond ;
- « FOREGROUND_COLOR » : pour la couleur d'avant-plan ;
- « HORIZONTAL_ALIGNMENT » : pour le type d'alignement horizontal ;
- « VERTICAL_ALIGNMENT » : pour le type d'alignement vertical ;
- « FONT » : pour la police utilisée dans la cellule ;
- « BORDER_STYLE » : pour le type de bordure de la cellule ;
- « IMAGE » : pour créer une image (par exemple une case à cocher !) ;
- « GRADIENT_BACKGROUND_COLOR » : pour créer un gradient de couleur pour l'arrière-plan (utilisé seulement par le « GradientBackgroundPainter ») ;
- « GRADIENT_FOREGROUND_COLOR » : pour créer un gradient de couleur pour l'avant-plan (utilisé seulement par le « GradientBackgroundPainter ») ;
- « PASSWORD_ECHO_CHAR » : pour créer un rendu de type « mot de passe » (utilisé seulement par le « PasswordTextPainter » et le « PasswordCellEditor »).
Ces attributs sont liés à l'objet utilisé pour créer le rendu de la cellule. Pour cela les éléments utilisés implémentent l'interface « ICellPainter » et celui utilisé par défaut est un « TextPainter ». D'autres rendus sont disponibles directement, dont nous donnons une liste ici :
- « TextPainter » : rendu le plus simple, textuel ;
- « VerticalTextPainter » : rendu sous forme de texte vertical ;
- « PasswordTextPainter » : rendu textuel pour mots de passe, avec des caractères spéciaux ;
- « LineBorderDecorator » : crée une bordure sur la cellule ;
- « PaddingDecorator » : crée un « padding » (marge interne) sur la cellule ;
- « BeveledBorderDecorator » : rendu sous la forme d'un bouton ;
- « ImagePainter » : dessine une image dans la cellule ;
- « BackgroundImagePainter » : dessine une image en fond de la cellule ;
- « GradientBackgroundPainter » : dessine un gradient dans l'arrière-plan.
Vous trouverez plus d'informations sur le site officiel du projetNatTable - Styling ainsi que dans les exemples, rubrique « Styling ». Ci-dessous, un exemple de ce qu'on peut obtenir pour avoir des cellules entièrement personnalisées, dont la mise en place est décrite sur le site officiel.

VI-C. Éditer les cellules▲
L'édition des cellules fonctionne sensiblement sur le même principe que la mise en place du style. Par exemple, mettons en place l'édition sur notre colonne « Landing Aircraft Type » où nous avons déjà mis en place la case à cocher. Modifiez la classe « CellsExample.java » comme suit :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
// ...
private class AircraftTypeColumnConfiguration extends AbstractRegistryConfiguration {
@Override
public void configureRegistry(IConfigRegistry configRegistry) {
// ...
configRegistry.registerConfigAttribute(EditConfigAttributes.CELL_EDITABLE_RULE,
new IEditableRule() {
@Override
public boolean isEditable(int columnIndex, int rowIndex) {
// Seule la colonne "Landing Aircraft Type" est editable
return (columnIndex == 9);
}
@Override
public boolean isEditable(ILayerCell cell, IConfigRegistry configRegistry) {
return (cell.getColumnIndex() == 9);
}
});
// Creation de l'editeur sur la cellule
configRegistry.registerConfigAttribute(EditConfigAttributes.CELL_EDITOR,
new CheckBoxCellEditor(), DisplayMode.EDIT, LABEL_AC_TYPE);
}
// ...
Nous pouvons ensuite visualiser le résultat et constater que nous pouvons
modifier la valeur de la cellule.
Ici le mode d'édition est relativement simple, mais la NatTable permet de mettre en place des
mécanismes bien plus complexes que nous allons rapidement passer en revue. Tout d'abord, la
première étape pour rendre une cellule éditable est d'enregistrer dans le registre de
configuration une « IEditableRule ». Dans notre cas, nous avons autorisé
seulement l'édition sur la colonne « Landing Aircraft Type ». L'interface
« IEditableRule » propose deux implémentations par défaut :
« ALWAYS_EDITABLE » ou « NEVER_EDITABLE ».
Nous définissons ensuite l'éditeur à utiliser dans la cellule. La NatTable propose une série
d'éditeurs dont voici la liste avec le rendu associé à utiliser :
- « TextCellEditor » - « TextPainter » : pour éditer le texte tout simplement ;
- « CheckBoxCellEditor » - « CheckBoxPainter » : pour afficher une case à cocher ;
- « ComboBoxCellEditor » - « ComboBoxPainter » : pour une édition via une liste déroulante ;
- « PasswordCellEditor » - « PasswordTextPainter » : pour une édition d'un mot de passe.
Notez que le « TextCellEditor » est l'éditeur par
défaut. Par exemple, si vous utilisez la règle
« IEditableRule.ALWAYS_EDITABLE » dans notre exemple, vous pourrez
éditer le contenu de chacune des cellules sans autre manipulation
supplémentaire pour l'affichage.
Si vous le faites, vous aurez par contre des exceptions en cascade à chaque édition !

En effet, la NatTable essaye d'affecter une valeur texte à des éléments qui ne le sont pas (des années par exemple qui sont des entiers dans notre modèle) ! Il est nécessaire de convertir les données vers le format voulu. Pour cela la NatTable met à disposition un ensemble de convertisseurs de données dont nous donnons la liste :
- « DefaultDisplayConverter » : String <-> String ;
- « DefaultCharacterDisplayConverter » : caractère <-> String ;
- « DefaultBooleanDisplayConverter » : boolean <-> String ;
- « DefaultByteDisplayConverter » : byte <-> String ;
- « DefaultShortDisplayConverter » : short <-> String ;
- « DefaultIntegerDisplayConverter » : int <-> String ;
- « DefaultLongDisplayConverter » : long <-> String ;
- « DefaultFloatDisplayConverter » : float <-> String ;
- « DefaultDoubleDisplayConverter » : double <-> String ;
- « DefaultBigIntegerDisplayConverter » : BigInteger <-> String ;
- « DefaultBigDecimalDisplayConverter » : BigDecimal <-> String ;
- « DefaultDateDisplayConverter » : date <-> String (utilise le format local de date) ;
- « PercentageDisplayConverter » : double <-> String (par exemple « 23 % » devient 0.23).
Évidemment, rien ne vous empêche de créer votre propre convertisseur,
en étendant la classe par défaut « DisplayConverter »,
comme nous l'avons fait précédemment pour convertir le type de vol
(« Passenger » ou « Freighter ») en booléen.
Pour pouvoir traiter les erreurs de conversion, il est nécessaire de déclencher
une exception de type « ConversionFailedException ».
De la même manière, les données doivent être validées avant d'être
enregistrées dans le modèle. Pour cela, la NatTable vous permet d'enregistrer la stratégie
de validation en étendant la classe « DataValidator ». Si la validation
échoue, il est nécessaire de déclencher une exception de type
« ValidationFailedException ».
Si une des deux exceptions citées ci-dessus intervient, il est nécessaire de donner un retour à
l'utilisateur. Pour cela, encore une fois, la NatTable propose différentes stratégies, à
vous de choisir celle qui convient le mieux :
- « LoggingErrorHandling » : stratégie par défaut, crée simplement un log de l'erreur ;
- « DiscardValueErrorHandling » : ferme l'éditeur de valeur ouvert sans mettre à jour le modèle ;
- « DialogErrorHandling » : permet via une boîte de dialogue d'annuler la valeur entrée ou de la modifier. L'annulation ferme l'éditeur sans mettre à jour le modèle, sinon l'éditeur est laissé ouvert pour permettre la modification ;
- « RenderErrorHandling » : utilisé pour le rendu sur les valeurs entrées directement dans la cellule, sans éditeur. Affiche la valeur en rouge dans le cas d'une erreur de conversion/validation.
Enfin, on peut afficher une décoration sur la cellule qui affiche un tooltip
à propos de l'erreur lorsqu'elle intervient. Vous trouverez plus d'informations sur
l'édition et les concepts associés sur la page idoine du site
officielEdition sur le site officiel NatTable.
Sans plus attendre, mettons en œuvre ces concepts sur notre NatTable ! Pour cela, nous allons
simplement mettre en place un mécanisme d'édition de l'année. C'est un entier sur quatre
chiffres, que nous souhaitons compris entre 2005 et 2013, inclus. La première étape est de
créer un « label » sur notre colonne « Year ». Puis nous
rendons la colonne « Year » éditable dans notre règle d'édition. Enfin
nous créons l'éditeur, définissons les stratégies de validation et de conversion et
d'affichage des erreurs, ainsi que la décoration.
En lançant notre exemple, nous pouvons activer l'édition de la cellule soit en cliquant, soit en appuyant sur F2 et nous pouvons observer les erreurs qui s'affichent lorsque les entrées sont invalides.



VII. Persistez !▲
Toute la configuration de la NatTable peut être enregistrée afin d'être
rechargée automatiquement au prochain affichage. Les éléments enregistrés
incluent, sans y être limités, les éléments suivants : ordre des
colonnes, colonnes cachées, tri sur les données, groupement des colonnes, filtres sur
les lignes.
La sauvegarde de l'état se fait grâce à la méthode « saveState » de la
NatTable. Il est sauvé dans un objet « java.util.Properties », autrement dit un
fichier clé/valeur séparés par le signe « = ». La restauration quant
à elle se fait par la méthode « loadState » à partir d'un fichier
Properties.
Il est évidemment possible de sauvegarder d'autres données particulières dans ce fichier
« Properties », en appelant la méthode
« registerPersistable(IPersistable) » sur un objet de type
« ILayer ».
VIII. Liens utiles▲
Vous trouverez ci-dessous une sélection de liens qui pourraient vous être utiles lors de la mise en œuvre de la NatTable.
IX. Conclusion▲
Au travers de cet article, nous avons découvert toute la puissance de la NatTable. Bien
entendu, il en reste beaucoup à dire, tant ce composant est riche en possibilités. Pour
aller plus loin, vous pouvez étudier les exemples, dont l'installation est décrite en
annexe.
Grâce à la NatTable, vous pourrez proposer aux utilisateurs de votre application un rendu et des
fonctionnalités très complètes en un minimum de temps par rapport aux composants
classiques.
X. Remerciements▲
Tout d'abord, nous ne pouvons que féliciter toute l'équipe de développement de ce composant pour la mise en place de ses fonctionnalités. Je remercie ensuite Mickaël BARONProfil de Mickaël BARON et Marc PEZZETTI pour leur relecture technique ainsi que Claude LELOUP pour sa relecture orthographique.
XI. Annexe : lancer les exemples▲
Tout d'abord, il est nécessaire de télécharger les exemples à cette adresseExemples NatTable 1.0.1. Vous devez ensuite les lancer en indiquant le plugin SWT spécifique à votre OS à utiliser dans le classpath.
java -cp org.eclipse.swt.win32.win32.x86_%version%.jar;NatTableExamples-1.0.1.jar
org.eclipse.nebula.widgets.nattable.examples.NatTableExamples« %version% » indique la version SWT que vous possédez. Dans mon cas, cela donne :
java -cp org.eclipse.swt.win32.win32.x86_3.100.1.v4236b.jar;NatTableExamples-1.0.1.jar
org.eclipse.nebula.widgets.nattable.examples.NatTableExamplesLors du lancement, une fenêtre s'affiche, vous permettant de lancer les exemples via double-clic. Vous pouvez consulter le code source de chaque exemple en cliquant sur le lien « View Source » en bas de chaque exemple.
